
The similarities between Python and Visual Basic for Applications (VBA) are strong. Python is of course a much stronger language, trying to do this the other way would have been way too painful (and possibly not doable). How much time does it take to extract info, convert code and run it? Find out..
If you read my second post in this series you saw that I manually ported the “VBA macro” code from a pretty complicated infection to Python to see what it could do. I needed to do that to understand how it would look in Python so I could write the virtual world around it and get more understanding of the language. This does take me back to the late 90’s and some other sandbox.
Now I have the first version of the automatic version done. It’s doing the same job as my manual task, but on it’s own. Good feeling, but that wasn’t easy. As I described in part 2, there are two major components.
We start with the tool that can decompile any document-format, extract the VBA source-code, extract UserForm information, Excel workbook sheet-information etc. It can also provide file IO directly to each extracted stream, in case some application-support class API needs to get read data directly to make an answer (e.g. properties from WordDocument etc). It basically provides the following JSON after it’s run:

As you can see, it’s just provide the links from the sample to where the various pieces of information are located to the translate program (vba2python.py). If we take a look at e.g. userform2_source, it’s all the source we could decompress form the UserForm2 stream in the VBA project of the original Word document:
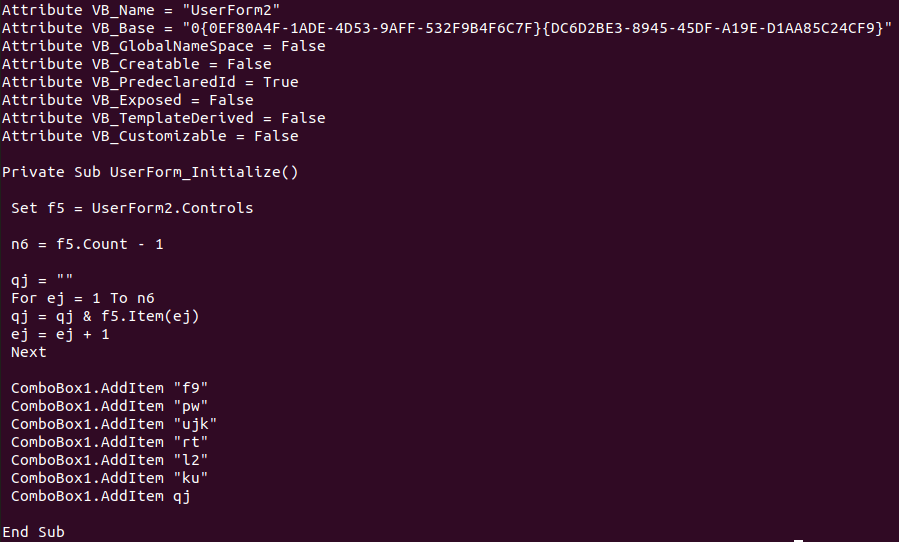
First you see a lot of attributes statement, then the function UserForm_Initialize(). If we look at the same file for data initialized by the UserForm2, it looks like this (omitting quite a few as I don’t want to fill too much space):

Basically it’s just a listing of all the indexes, identifiers and values of each UserForm2 variable. All “VBA environment” code is loaded via an “applicationworld.py” which defines the objects (Macro, UserFormItem, Sheet, Application etc) and the API support (Now, CreateObject, etc…)
The task for vba2python is then:
- Load the JSON with links to data
- For each macro-stream in the JSON:
- Create a Macro class for each name, with a __init__ that populates calls the inherited init, sets up the class UserForm data and calls the UserForm_Initialize “VBA” function if defined (converted to Python)
- Load and declare globals (if present)
- Figure out what constitutes as the various functions (name, parameters), start of code and where it ends
- It then carries a modulestate, so we know when we need to call constructors when we analyze the code (when an external class is referenced and not initialized, we need to so so there).
- Convert the rest of the source-code to Python from the VBA source-code pr function pr macro stream
- Call global macros exported, like “Document_close()”, a list is available.
The conversion is basically doing some very light tokenization, trying to identify challenges that needs to be rewritten from VBA to Python, add the “self.” reference if the sample code is using a class-variable etc. This turned out to be some lines of code. I totally get that in version 1 this doesn’t understand the code, it just nudges it to fit the bill.
It then dumps all these classes to stdout after a header, which can be stored to a file – say 1.py:
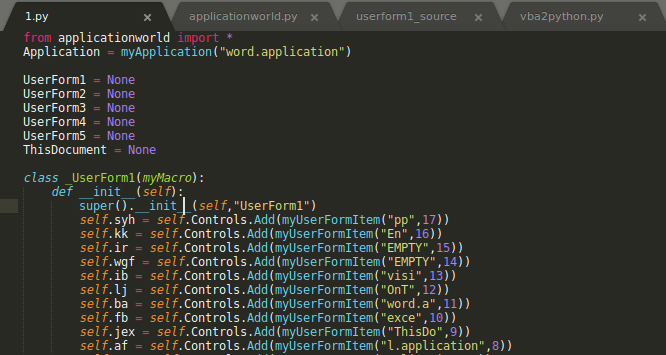
When you get to ThisDocument it gets fun:
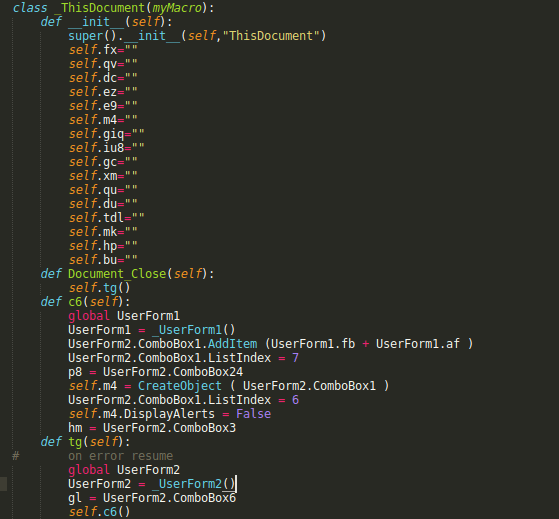
From this you get the gist of how it will go down.. One challenge I’ve seen is the simple For loop. In VBA you have:
Set f5 = UserForm2.Controls
n6 = f5.Count - 1
qj = ""
For ej = 1 To n6
qj = qj & f5.Item(ej)
ej = ej + 1
NextIncredible simple. It loops through items 1 to n6 with step 1 – but the code in the body of the for-loop adds a 1 to the counter which makes it step 2. To replicate this in Python, I couldn’t just use a “for ej in range(1,n6):” as range(1,n6) creates a list of entries and you can’t modify the step (will just be ignored as it’s following a list). Trying to understand the code within the for-loop body is possible so you “learn” that this is a step 2 operation. I ended up rewriting the code to a while loop:
ej = 1
while ej < n6:
qj = qj + f5.Item ( ej )
ej = ej + 1
ej += 1
That gives one line to initialize the start value, a while loop with the same exit strategy, and at the end of the while-body I add a manual step. That the sample adds it’s own step then becomes irrelevant. However, I can see complicated things here too, especially with the use if “continue” etc – so I need to find a better approach. More homework…
The output when running 1.py is identical to the manual conversion in part 2.

Now to the interesting part.. How much time does this take to extract data, rebuild the VBA source to Python and run this to analyze this sample?
| Time to create the linking JSON and extract the document info: | real 0m0.133s |
| Time to build 1.py using vba2python.py | real 0m0.045s |
| Time to run 1.py | real 0m0.041s |
| Total | real 0m0.219s |
So in 219 milliseconds we had the result, and given this is first version and tons of more stuff is to be done – it gives promise that this can be performed on any gateway to do proper inspection. Time to add more support and resilience to the tool! This gives good motivation for more hours poured into this “research project” as the days go by.
What benefits could this add to an existing product, given that it would cover a wide range of samples?
- No need to send virtually any document to a sandbox VM for analysis (cost, time, privacy), even exploited documents have some “generic” properties that can be detected.
- Possibility of doing “sandbox light” of macro-code (for now, VBA) inline as it’s so fast (NGFW, proxy etc) – without much cost.
- Get the threat intelligence much faster than before, handle bigger volumes than a Sandbox VM?
- Scalability like no other as it’s light, fast and written in Python3 and runs in milliseconds?
This is definitely worth pursuing; all that is needed is time and hard work.
