If you have followed my lasts posts, it’s been focused on VBA macros and getting them to run on a Python platform. I spent a lot of time understanding the VBA world and how it could work in the Python world. I manually converted the code and then I built automation to convert the complicated sample of the second post. What I didn’t know then, building automation for the first sample was a paramount task. What was I thinking …
This has been a week of ups and downs. I thought I’d have this done by Monday. It’s not until you face each line logically and their dependencies you understand how complicated this can get. I am not going to give all the secrets away, instead – I will show you some the Python 3.x generated code for this sample – with the VBA macro it replicated. It has been such a headache to get this working generically.
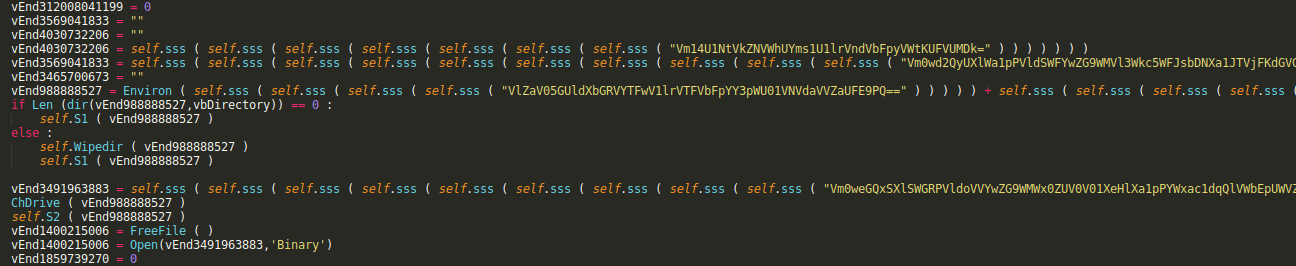
If we start with what we want to see – the result

Basically you see python3 reading the JSON linking the sources of the VBA code from the document and piping this just through to another Python 3 instance which actually runs the generated code. All is done in 0.084 milliseconds. Yes, the same macro is run twice because there are two global macros both calling the same code.
The Python 3.x version of this sample (f5858eb5772eba0b6c066aebdd1efbdefed71a6a):
On the left you see the generated Python code and on the right the original VBA macro code.
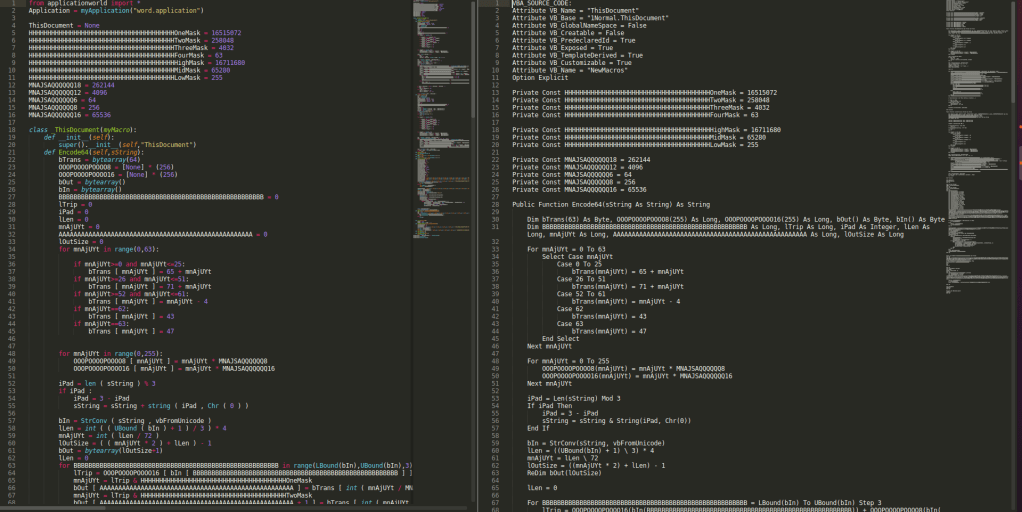


Only in a few areas the lines needed to be rewritten, and mostly it is possible to get it into Python with not too many tricks. That gets you 50% the way. Hard part are divide; in VBA it seems to generate a Integer, while in Python delivers a float which can’t be used for indexing, VBA not having [ when they index data in tables causes “fun” when you least expect it and a million more of those.. You need to carry context, what is what and where to reference everything correctly. What’s what makes this so much “fun”.
Could this tool be useful out there? My initial thought is a micro-service running in a Docker you just pull down and “check a file” with Curl in a few milliseconds – or just keep it as commandline tool? I have reserved LibNotFound at GitHub for my tools once they are ready for the public and I’ve found a licensing model that works.

One thought on “Automatically generate Python 3.x from malicious VBA macros”